
★この記事を読む前に★
この記事で取り上げているMMR(MacromillR)とは、マクロミルの社内ツールです。
統計解析向けのプログラミング言語であるR言語の様々なパッケージを、だれでも簡単に使えるように独自開発を行い、ツール化したものです。
Rのコードを書かずに、Rの開発・実行環境を整えていなくても、Rの便利で強力なデータ集計・分析機能を利用することができます。
こんにちは。リサーチプラットフォームUの脇田光です。皆さんは、壁の薄いアパートって住んだことがありますか?僕はあります。この記事で取り上げているMMR(MacromillR)とは、マクロミルの社内ツールです。
統計解析向けのプログラミング言語であるR言語の様々なパッケージを、だれでも簡単に使えるように独自開発を行い、ツール化したものです。
Rのコードを書かずに、Rの開発・実行環境を整えていなくても、Rの便利で強力なデータ集計・分析機能を利用することができます。
初めて一人暮らしをしたのが杉並区の木造アパートだったのですが、建物に居る全員が同居人かってくらいに音が漏れ聞こえてきます。朝7時くらいになると隣人宅のキッチンから「トントントン…」と何かを切るまな板の音がし始め、その音で僕も目覚める生活を送っていました。
新婚なら幸せな朝の風景ですが、ただの他人なので僕に朝食は用意されていません。起床損です。ちなみにその隣人、夜になるとめちゃくちゃ大声で「夜に駆ける(YOASOBI)」とか歌うので最悪でした。
リモートワーク生活も長引くことが予想されたので、当然引っ越しを検討したのですが、別に住みたい町があるわけでもありません。引っ越したいが行くところがない、と悩んでいる間にも劣悪になる隣人関係…。ああ、一体どうしたらいいのか、「色々な町がどういう要素を持っているのか」が分かれば、どこに引っ越せば良いのかが見えてくると思うのですが、外出がしづらいこの頃、転居先を見つけるもの一苦労です。
 /脇田さん、それMMRで因子分析してみてはいかがでしょうか?\
/脇田さん、それMMRで因子分析してみてはいかがでしょうか?\

池田さん!!!!!
<ご紹介>
![]()
池田拓郎
リサーチプラットフォームユニット 技術研究グループ所属
2014年10月入社。アナリティクスグループで購買データの集計・レポーティング業務ののち、技術研究グループにてBPRのためのツール開発を行う。
Excel VBA、R、shiny、Tableau、Alteryxなどに精通する。MMR開発者。
しかし池田さん、何をどうやって色んな町の要素を可視化すればいいのでしょう?
MMRには因子分析機能があるので、統計局からさまざまな町に関するデータを集めて因子分析してみましょう。

そもそも、MMRってどんなツールでしたっけ?
MMRは「MacromillR」の略称で、R言語のさまざまなパッケージを簡単に扱えるようにしたwebアプリです。テキスト解析だけではなく、因子分析やクラスタリング、因果分析やコレスポンデンス分析、SEMなどの多変量解析にも対応しています。
なるほど、完全に理解しました。
例えば、以下のように東京・埼玉・神奈川の人口統計データがあったとします。
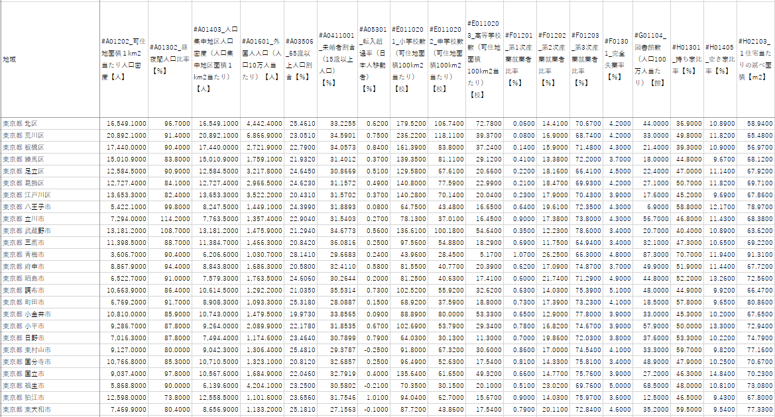
データ出典:estat市区町村データ ※データの年度は「各データの最新年」を採用
一部古いデータもあるため、近年変化の大きい市区は現実とのズレがでる可能性あります。
143の市町村に関する人口統計データですね。人口密度から犯罪件数まですごい量です。
このデータを因子分析にかけることで、大量にある変数データ(人口密度や犯罪件数などの項目)たちの裏にある“共通因子”を見つけます。そして、現在各行に入っている143の市町村がどの程度“共通因子”の影響を受けているのかを“得点化”してみましょう。
※IQ2のわきたにでも理解しやすいよう、ざっくりご説明いただいております。
詳しい因子分析についてはこちらから
……?(※それでも理解ができていない人)
とりあえずMMRを使ってみましょう(笑)。まずは、MMRにアクセスします。
今回は「データの名前になる列」はA列の“地域”、「分析する列(観測変数)」は“それ以外のすべての列”が選択されている状態なので、特に変えずに進めます。
その下の因子数はどうしたらよいでしょうか?
MMRには最適な因子数を探索する機能がありますので、そちらを試しましょう。

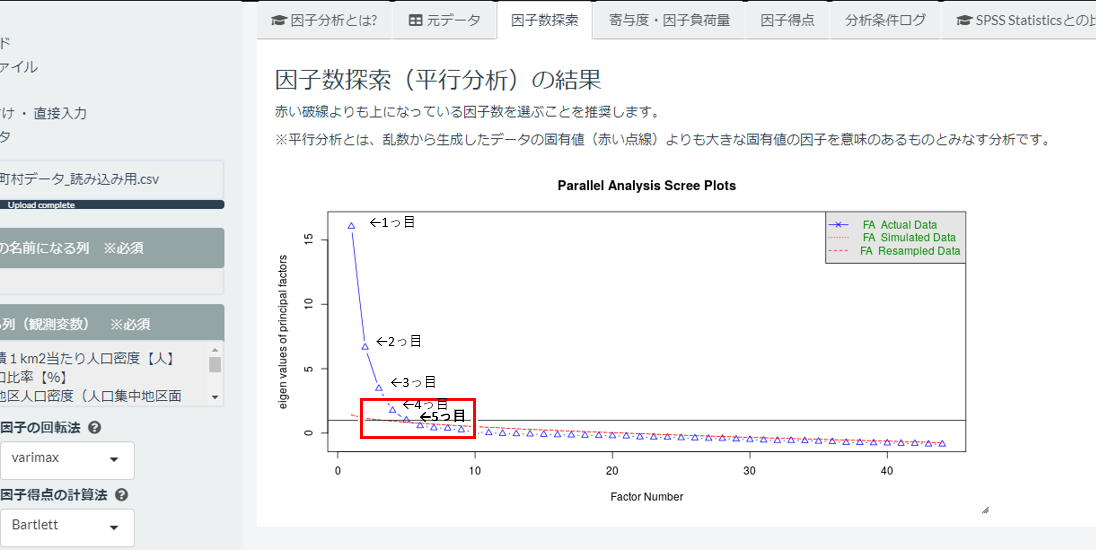
すると、右側の画面が切り替わり、因子数探索の結果が描画されます。
この△マークが因子を指していて、上から1、2…と数えていくわけですね。
そうです。下部の赤い点線より初めに上回ったときの因子数が最適な因子数と提案しているので、今回は5個になります。
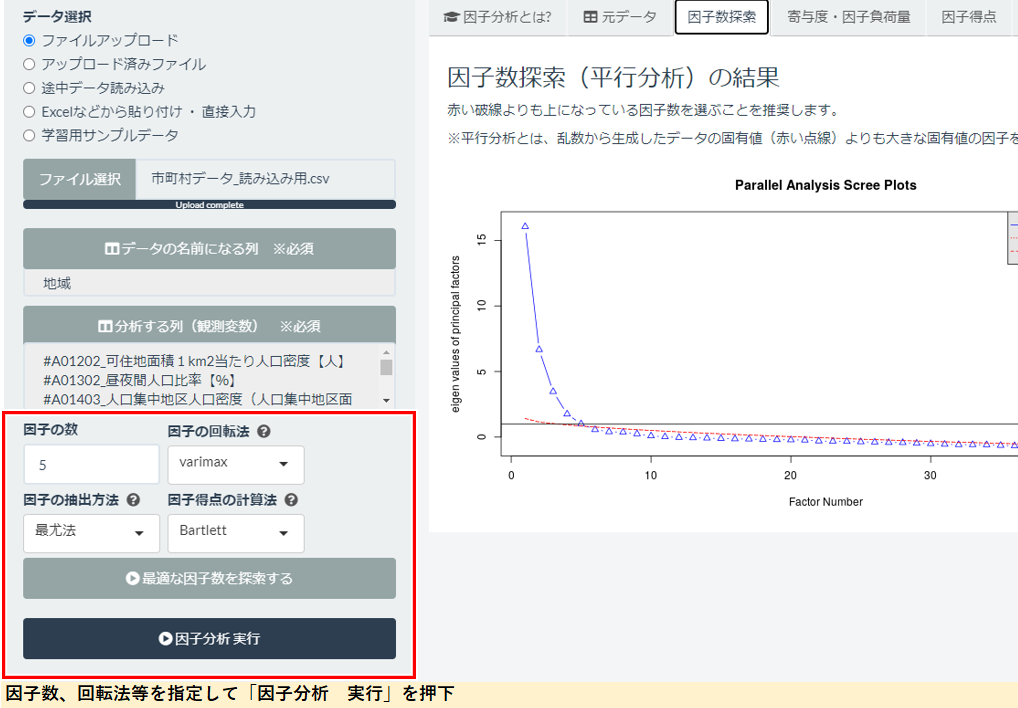
それでは因子数は5、回転法はvarimax、その他はデフォルト設定のまま、因子分析を実行しましょう。
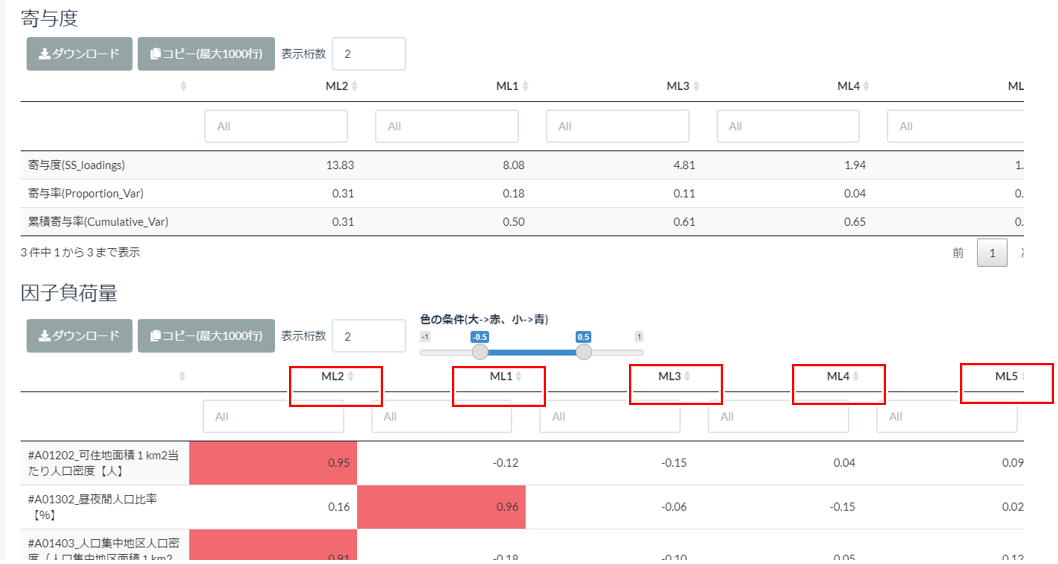
画面が切り替わって、なんか色々出てきました!
設定した因子数に従って、ML1~ML5という因子が抽出されています。
このMLというのが、各市町村の裏に持っていた共通点ということになるわけですね。
次の作業としてこの各因子に名前を付けていくのですが、その時に使えるのが画面下部の「因子負荷量」です。
「因子負荷量」はML(因子)が元の各列からどの程度影響を受けているのかのスコアになるので、因子負荷量スコアの強弱をみてML1~5まで名称をつけていきましょう。
「因子負荷量」はML(因子)が元の各列からどの程度影響を受けているのかのスコアになるので、因子負荷量スコアの強弱をみてML1~5まで名称をつけていきましょう。
例えばML2なら、人口密集に関する項目が高く(赤く色づいている)、住宅延べ面積や持ち家比率が低い(青く色づいている)ので、【集合住宅密集地】などいかがでしょうか?
そうですね。この名称付けの部分はどうしても分析者の主観によるところが大きくなってしまうので、様々な項目との関連を考えながら慎重に命名してみてください。
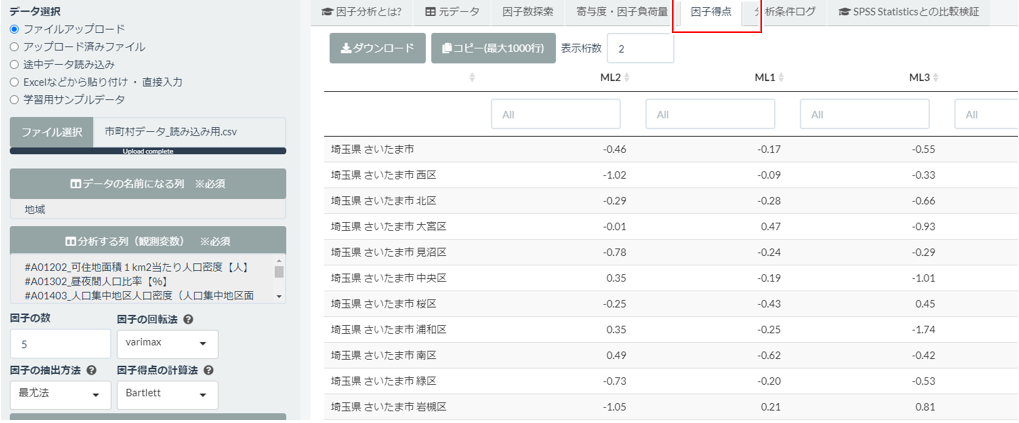
1つ右のタブには「因子得点」というのが出ていますね。
はい、因子得点では、このデータでいうと143の市町村が各因子にどの程度影響を受けているのか点数化されています。
お~、これで各市町村ごとに因子の影響度が見られるのですね!これでその町がどういう要素を持っているか見れそうです…!
多変量解析ってロジックが複雑でとっつきにくい印象があったのですが、最後のアウトプットがどういう意味なのかが分かるだけでもぐっと使いやすくなりますね。
多変量解析ってロジックが複雑でとっつきにくい印象があったのですが、最後のアウトプットがどういう意味なのかが分かるだけでもぐっと使いやすくなりますね。
そうですね~。MMRはとにかく手軽に集計できることが強みなので、気軽に結果を色んな手法でみたいときは向いていると思います。使いやすさが結果の導きやすさにも繋がるので、開発側としては皆さんにどんどんご利用いただいて要望をお聞きしたいですね。
データの収集からアウトプットの作成まで、ありがとうございます!ちょっと因子得点を観察してみようと思います!

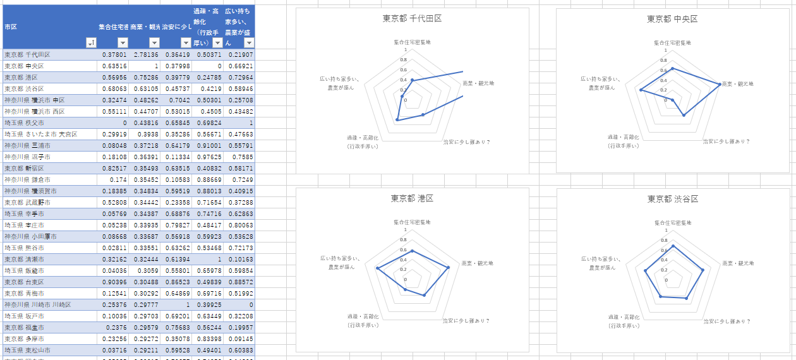
こうすると各市町村が各共通因子にどの程度影響を受けているか一目瞭然です。

こうやってレーダーチャートを並べているとデータを分析している人っぽくなってかっこいいですよね。
――――――――――――― 後日 ―――――――――――――
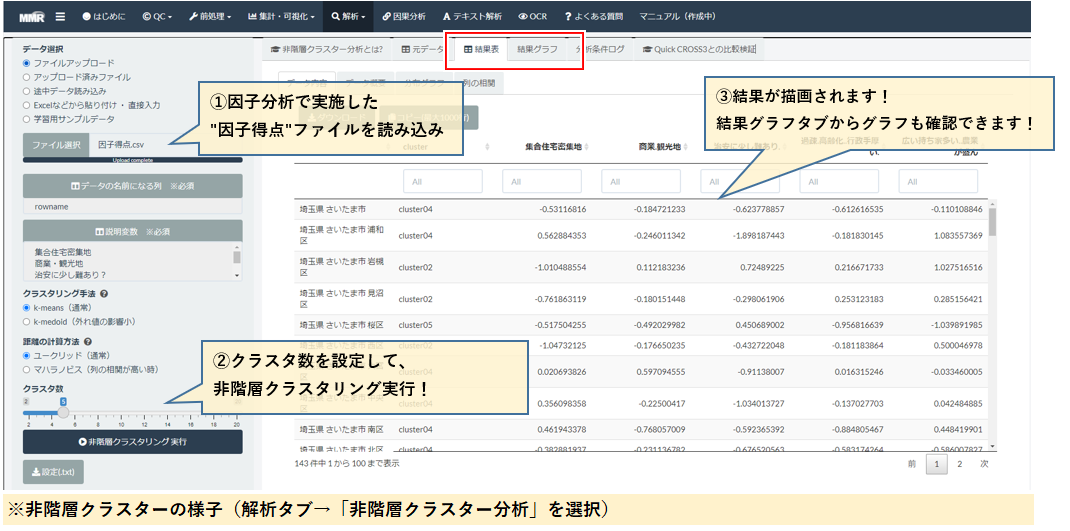
レーダーチャートに影響されすぎて、ちょっと自分を見失ってしまいました。その後、池田さんから適切なアドバイスを受けて、MMRの階層クラスター分析(デンドログラム)や非階層クラスター分析(k-means)を使ってクラスタリングを行いました。非階層クラスター(クラスター数20)の結果がこちら(画像は一部抜粋)。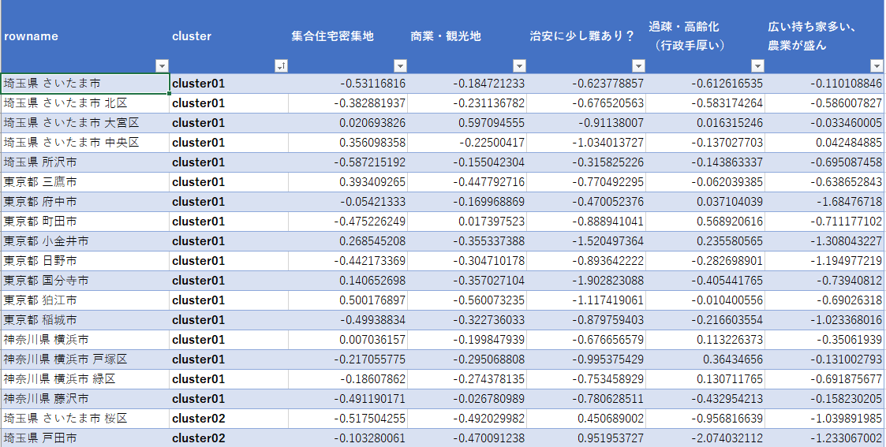
例えば僕が以前住んでいた杉並区に近い町は練馬区や中野区、神奈川だと横浜市西区や川崎市幸区とのこと。まずはレーダーチャート(因子得点)で重視するポイントを決めて、その町の所属クラスタから転居先を決めてみると良いかもしれないです。
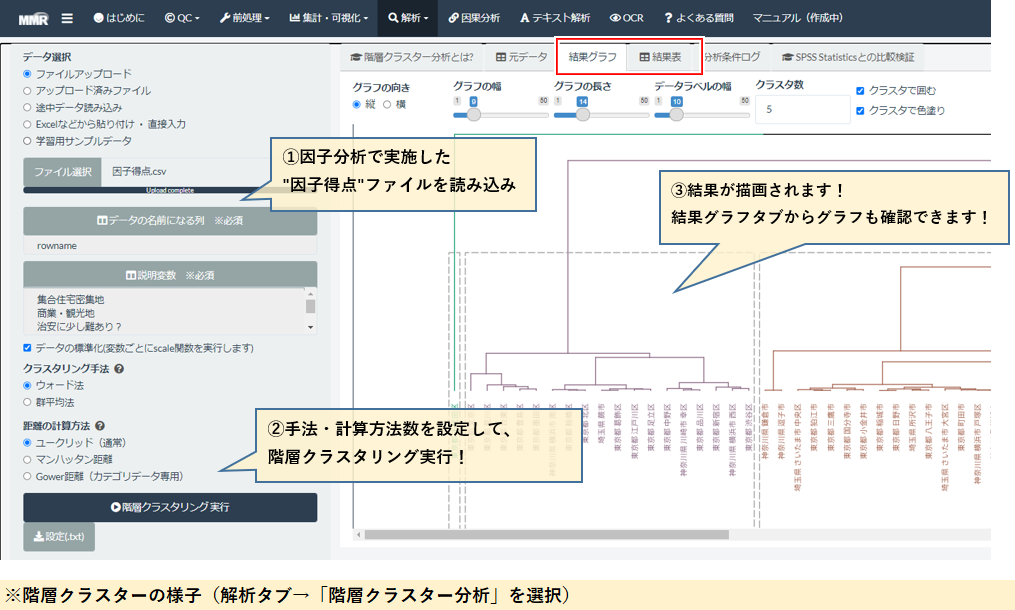 ちなみに因子分析データを階層クラスタリングするとこんな感じのマップ、
ちなみに因子分析データを階層クラスタリングするとこんな感じのマップ、

非階層クラスタリング(k-means)結果をt-SNE(データを二次元マップ化する手法)でマップ化するとこんな感じに描画されます。もちろんすべてMMRでアウトプットしたものです。
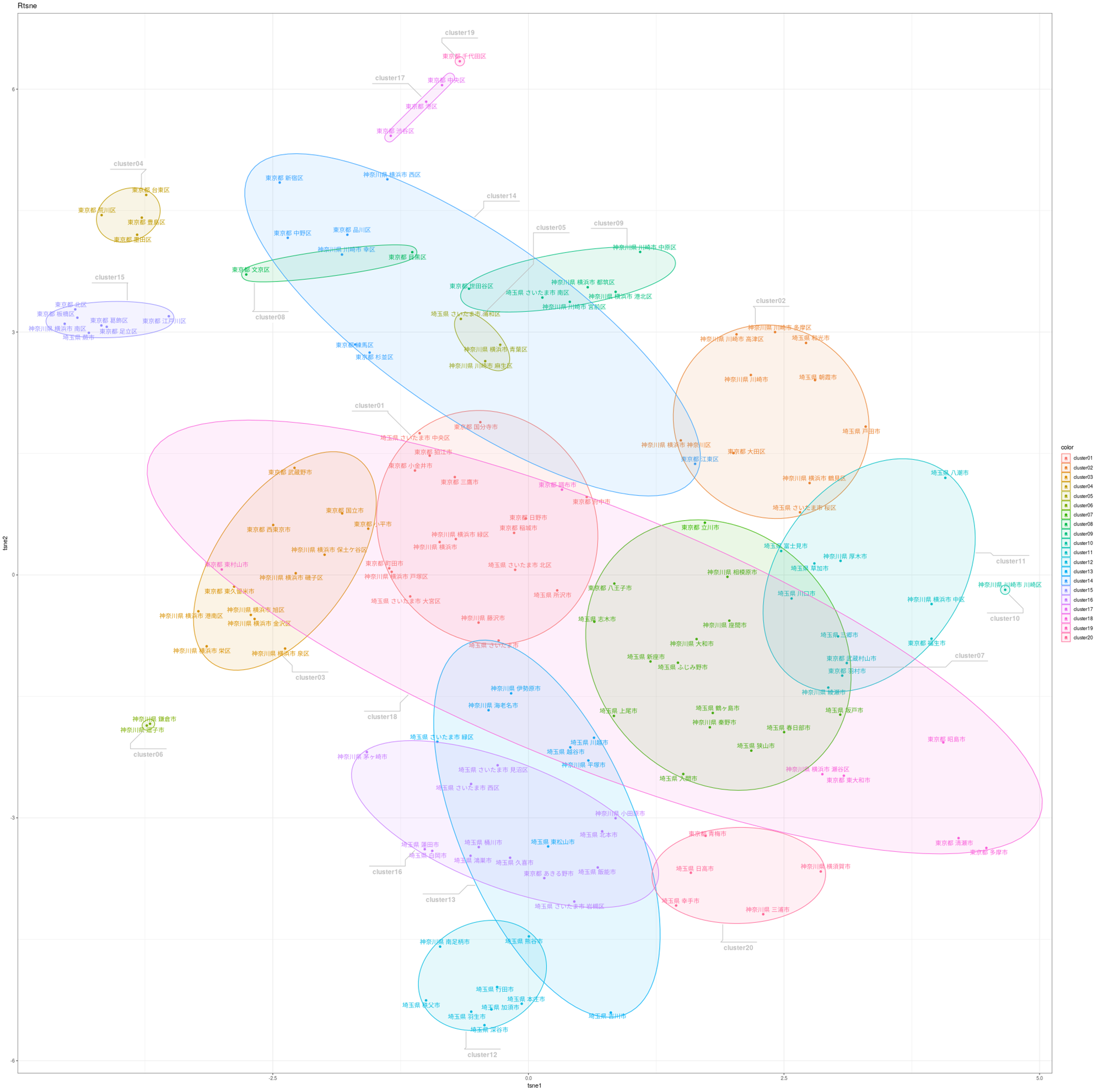
記事内で作成したデータを見て、あなたのお住まいの町がどういう共通因子の影響を持っていて、同じクラスタにどんな町があるのか、ぜひ見てみてください。